Null Hypothesis Significance Testing Via Permutation Tests
A WebR Tutorial

The scenario
In this activity, we will work with data from a study conducted by Drs. Jake Hofman, Daniel Goldstein & Jessica Hullman.

In the experiment, participants were told they were athletes competing in a boulder sliding game against an equally skilled opponent named Blorg. The objective was to slide a boulder farther on ice than their opponent to win a 250 Ice Dollar prize, awarded to the contestant with the longest slide. They had the option to rent a “special boulder” — a potentially advantageous (but not guaranteed) upgrade expected to improve their sliding distance in their final competition. Participants then saw a visualization with statistics comparing the standard and special boulders. After studying the randomly selected visualization, the participants indicated how much they would be willing to pay for the special boulder and estimated their probability of winning with it.
Participants were randomly assigned to see one of the following visualizations that they could use to decide how much to pay for the special boulder and how certain they were that it would help them win. These four visualization types are shown below:
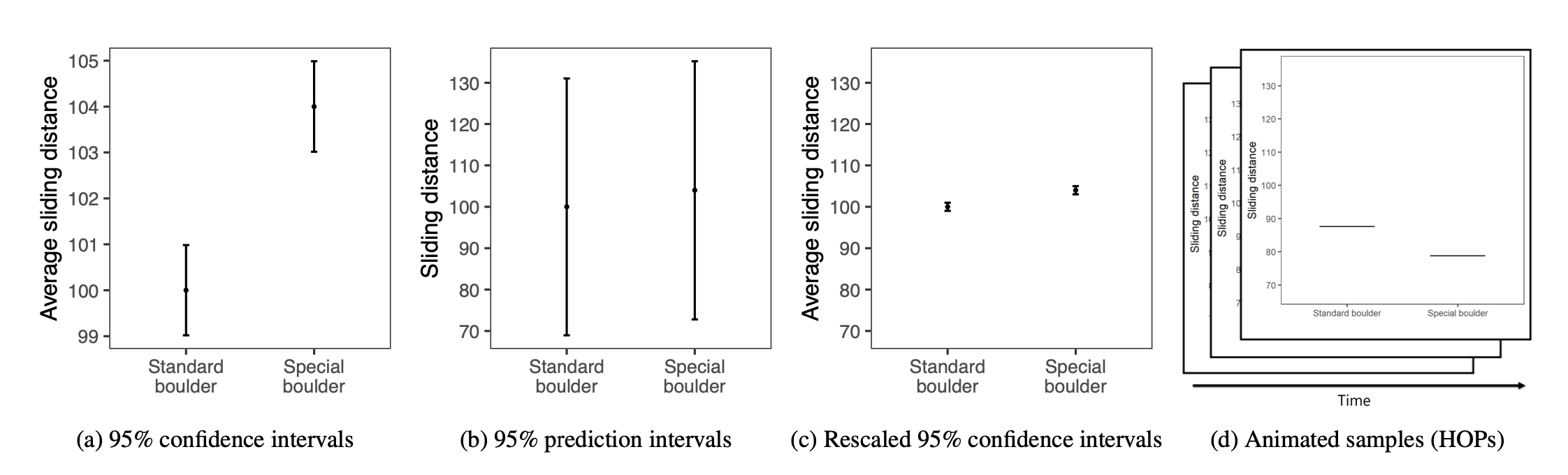
The conditions, moving from left to right, are described as:
- A 95% Confidence Interval (CI)
- A 95% Prediction Interval (PI)
- A rescaled 95% CI (CI_rescaled, i.e., the y-axis is rescaled to have the same range as the PI graph)
- Hypothetical Outcomes Plots (HOPS), which show uncertainty through a series of animated frames that depict samples from underlying distributions.
Additionally, participants were randomly assigned to see either a small effect (probability of winning with the special boulder = 0.57, where 0.5 indicates even odds) or a large effect (probability of winning with the special boulder = 0.76). In this activity, we’ll focus on the participants who were randomly assigned to see visualizations depicting a large effect size.
We’ll consider two variables in this activity:
graph_type provides the type of graph the participant viewed — this is the randomly assigned condition. The types are called CI, PI, CI rescaled, and HOPS (corresponding to the descriptions above).
The outcome that we will consider here is called wtp_final. It represents the amount of money (in Ice Dollars) that the participant reported they would pay to rent the special boulder.
Does willingness to pay differ by condition?
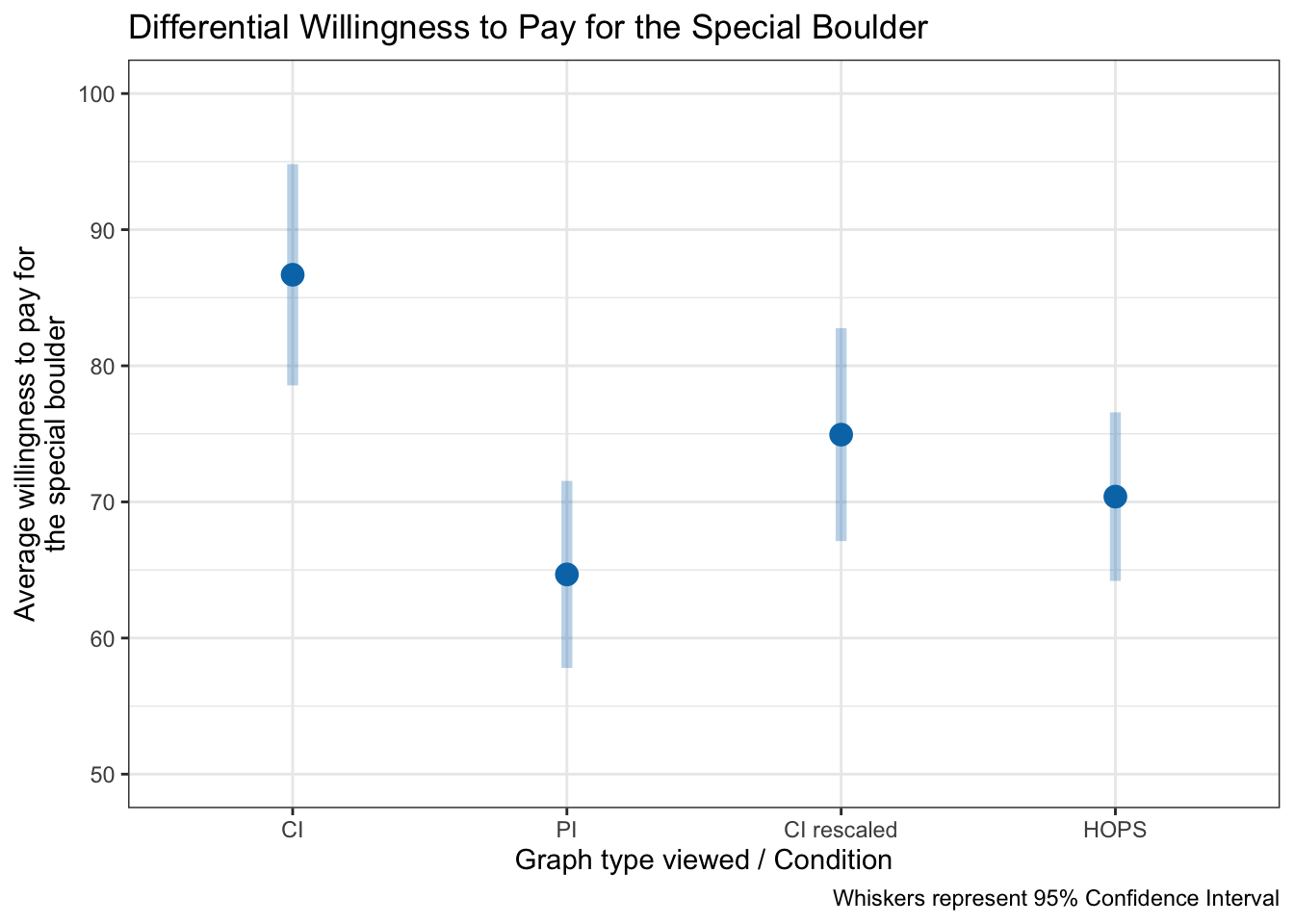
The graph below shows the average willingness to pay for the special boulder in each visualization condition, with 95% confidence intervals to reflect variability.
In this graph:
Each point shows the sample mean willingness to pay for the special boulder in each visualization condition.
Error bars represent 95% confidence intervals for the group means. They provide a sense of the precision of our estimates — narrower bars indicate more precise estimates.
What is a permutation test?
When we run a statistical test, we want to know if an observed difference—like how much more participants are willing to pay for the special boulder in one condition versus another — is just random chance or reflects a real effect.
A permutation test answers this by showing what the data would look like if there were no real difference between the conditions. We do this by repeatedly shuffling the group labels in the dataset. Each time we shuffle:
We reassign each participant’s willingness to pay to a random condition.
We recalculate the mean difference between conditions.
Repeating this many times gives us a null distribution: the differences we’d expect purely by chance if the null hypothesis were true. Finally, we compare our observed difference to this null distribution. If it falls far into the tails—much larger or smaller than what we’d expect by chance—it suggests the difference is unlikely to be random and may reflect a genuine effect.
To see an example, let’s perform one shuffle.
# shuffle data
shuffled_groups <-
df |>
mutate(shuffled_group = sample(graph_type))
shuffled_groupsNotice that the data frame now has the “real condition” (graph_type) and a randomly shuffled condition (shuffled_group).
We need many shuffled datasets to accurately assess how unusual our observed difference is. Therefore, in a permutation test, we don’t rely on a single shuffle. Instead, we repeatedly shuffle the group labels — thousands of times. For each shuffle, we:
Randomly reassign participants to groups.
Calculate the mean willingness to pay for each shuffled group.
Record the difference between the shuffled group means.
Repeating this process produces a null distribution of mean differences — what we’d expect to see purely by chance if the null hypothesis were true. Comparing our observed difference to this null distribution shows whether it’s likely due to random variation or reflects a real effect.
The graph below recreates the earlier plot using 1,000 shuffled datasets. It displays the observed group means along with their variability under repeated random shuffles. While the error bars in the previous graph summarize the uncertainty around our observed group means (i.e. the familiar 95% confidence intervals), this plot shows what those group means would look like if there really were no effect. Here, each point is the average willingness‐to‐pay from one of 1,000 random reassignments of labels, and the shaded bands mark the central 95% region of that null distribution. In other words, these “permutation intervals” visualize the range of mean differences we’d expect purely by chance under the null hypothesis.
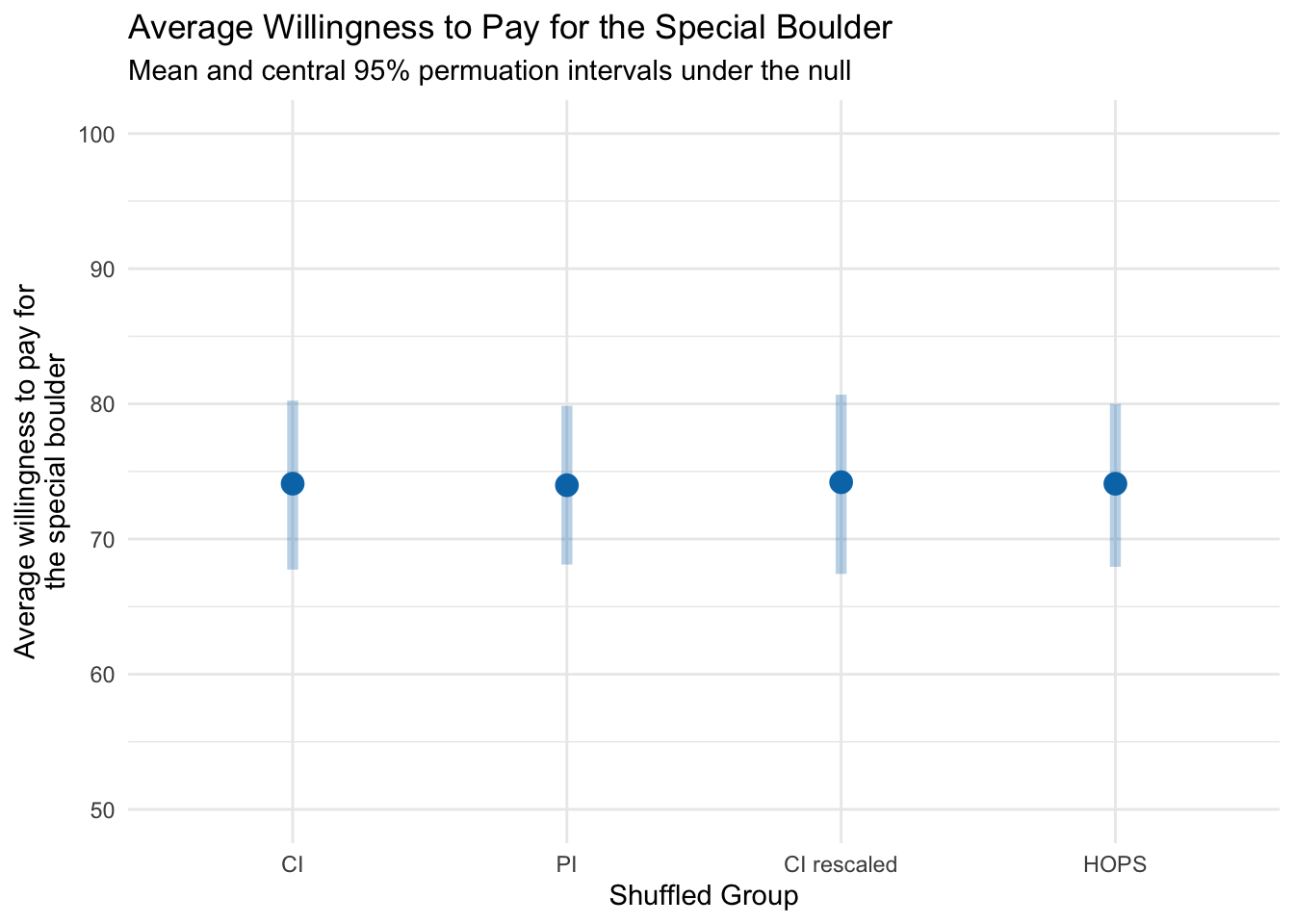
As expected, the shuffled groups show almost no difference in willingness to pay, reflecting that random reassignment does not create a real effect.
Goal of this activity
In this activity, we will investigate whether the average willingness to pay for the special boulder differs between two visualization conditions (e.g., CI vs. PI).
You will:
Select two conditions and calculate the observed difference in mean willingness to pay.
Evaluate how unusual that difference is under the null hypothesis that there is no true effect.
By the end of this activity, you’ll interpret the resulting p‑value and gain intuition for deciding whether an observed difference likely reflects real group differences or is simply due to chance.
Conduct a null hypothesis significance test using a permutation test
Let’s use the permutation test approach to determine if there is a significant difference in willingness to pay for the special boulder between two selected groups.
Step 0: Import the data
Please click Run Code on the code chunk below to import the data.
Step 1: Choose two conditions to compare
Next, choose two conditions to compare. The code below will assign one condition to be called Group A, and the other condition to be called Group B. By default HOPS and PI are compared, but you can change these to compare other groups.
- CI
- CI rescaled
- PI
- HOPS
The code also creates a dummy-coded variable to compare Group B to Group A (which we’ll use later in the activity).
Press Run Code to create the subsetted data frame for the investigation.
Step 2: Compute descriptive statistics
Compute average response for each condition
Here we ask:
What is the average willingness to pay for the special boulder in each of your selected conditions?
Press Run Code on the code chunk below to compute the mean and standard deviation of willingness to pay for the special boulder in your selected conditions. The code also calculates the sample size of each group.
Compute difference in average response between conditions
Here we ask:
What is the mean difference in willingness to pay between the two groups?
Press Run Code to calculate the difference in willingness to pay between these two groups.
Make a descriptive plot
Last, let’s create a plot of the raw data. Press Run Code to visualize the distribution of willingness to pay for these two groups.
Step 3: State the null and alternative hypothesis
Null hypothesis: \(H_0: \mu_{\text{GroupA}} = \mu_{\text{GroupB}}\) (the two means are equal). Or equivalently: \(H_0: \mu_{\text{GroupA}} - \mu_{\text{GroupB}} = 0\) (the difference in means is zero)
Alternative hypothesis: \(H_a: \mu_{\text{GroupA}} \neq \mu_{\text{GroupB}}\) (the two means are not equal). Or equivalently: \(H_a: \mu_{\text{GroupA}} - \mu_{\text{GroupB}} \neq 0\) (the difference in means is not zero)
Step 4: Mimic the sampling distribution for the difference in group means under the null hypothesis
Create shuffled datasets
Using permutations, we can approximate the sampling distribution of the difference in willingness to pay between the two groups under the null hypothesis. Press Run Code to perform 1,000 permutations, calculating the mean willingness to pay for each shuffled group in every iteration. This will take a few minutes.
Take a peek at the raw data and first three shuffled datasets
The graphic below shows how permutation works. The first panel displays the original data with the true group assignments, and the next three panels illustrate the first three shuffles of those assignments. Notice that after shuffling, the group labels no longer carry real meaning — any patterns that emerge are purely due to chance.
Compute the difference in the response across all shuffled datasets
Next, we’ll calculate the difference in mean willingness to pay between the two groups for every permutation. This value, which we’ll call null_diff, reflects the difference between the shuffled (randomized) group assignments in that permutation — not the real experimental conditions. Click Run Code to generate null_diff for all permutations
Visualize the sampling distribution under the null
Now, we can visualize the expected difference in willingness to pay between the two groups under the null hypothesis.
Earlier, you calculated the observed difference in willingness to pay between your two selected conditions. Locate that value on the x‑axis of the null distribution and consider: How extreme is this difference compared to what we would expect if the null hypothesis were true?
Step 5: Query the permutations
Tally extreme results
Our goal is to answer:
In how many of the permuted samples is the calculated difference between groups as extreme (or more extreme) than our observed difference between groups?
What’s the intuition?
If the null hypothesis is true, there is no real difference in average willingness to pay between the two groups.
Any difference we see is purely due to chance.
By shuffling the group labels thousands of times, we create a null world where the true difference is zero.
Each permutation shows us a difference we might expect by random chance.
How do we measure extremeness?
Because we are not predicting which group should have the higher mean, we use the absolute value of the differences.
A permutation is considered “extreme” if its absolute difference is greater than or equal to the absolute observed difference.
What we’ll do:
Mark each permutation as “extreme” if the absolute difference in means is at least as large as the observed difference.
Count the extreme cases to determine the fraction of permutations that are as extreme or more extreme than what we observed.
Press Run Code to tally the number of extreme samples.
Compute p-value
Here we ask:
What proportion of the permuted differences are as extreme as our observed difference?
From our tally, we can compute the fraction of permutations where the absolute difference in means is at least as large as the observed difference between the real groups.
This fraction is our empirical p‑value — the probability of seeing a difference this extreme if the null hypothesis were true.
A small p‑value means that such an extreme result would be unlikely by chance alone, providing evidence against the null and suggesting a possible real difference between the groups.
Step 6: Compute the standard deviation of the null distribution
The standard error (SE) reflects how much the mean difference in willingness to pay would vary by chance due to random sampling.
In a permutation test, we can estimate this by calculating the standard deviation of the mean differences across all 1,000 shuffled datasets. This gives us the spread of differences we’d expect under the null hypothesis, showing the typical variation if there were no real effect.
Press Run Code to compute the standard error.
Step 7: Calculate a test-statistic
How many standard errors away from zero is our observed difference between the two real groups?
To judge how unusual our observed difference is under the null hypothesis, we calculate a standardized test statistic:
Take the observed difference in willingness to pay: \(\bar{x}_B - \bar{x}_A\).
Subtract the null hypothesis value (0).
Divide by the standard error from the permutation distribution.
This standardized value tells us how many standard errors the observed difference is from the null, which is the foundation for significance testing.
The formula for the standardized test statistic is:
\[ t = \frac{(\bar{x}_B - \bar{x}_A) - 0}{SE} \]
Compute the standardized test statistic
Press Run Code on the code chunk below to compute the standardized test statistic.
Visualize the standardized text statistic alongside the sampling distribution under the null
We can visualize where our observed standardized test statistic falls relative to the null distribution — the distribution of standardized differences we would expect if there were truly no difference between the groups.
The shaded middle region represents the 95% of null test statistics that are closest to zero. If our observed statistic lands far in the tails, it’s unlikely under the null hypothesis — exactly what a p‑value quantifies.
Press Run Code on the code chunk below to produce the graphic.
On this graph, the darker gray area of the sampling distribution under the null denotes the critical boundaries, marking the middle 95% of the distribution. The green line shows the calculated standardized test statistic for the difference in willingness to pay between the two conditions that you selected, measured in standard errors from the null hypothesis value (0 — i.e., no difference between groups).
If the green line falls within the darker grey area, we cannot reject the null hypothesis (we lack evidence that the group means differ).
If the green line is outside the darker grey boundaries, we can reject the null hypothesis (indicating a significant difference between groups). In this example, such a result would suggest that the data visualization shown to participants affects their willingness to pay.
Can the null hypothesis be rejected for the comparison of your selected conditions?
Step 8: Test the hypothesis with an independent samples t-test
To test whether there’s a meaningful difference in means between two groups, we have two primary approaches: a non-parametric approach (e.g., the permutation test we just worked through) and a parametric/theory-based approach.
A two-sample t-test is a parametric approach, meaning it relies on certain assumptions about the data:
Normality: The sampling distribution of the difference in means should be approximately normal. This assumption is generally met if each group’s data is roughly normal or if the sample sizes are large enough (thanks to the central limit theorem).
Equal Variance: The variability (spread) in each group should be approximately equal.
If these assumptions are reasonable for your data, an independent samples t-test can be a powerful tool. Here’s how the t-test works:
Calculate the Mean Difference: First, we calculate the difference in means between the two groups.
Estimate the Standard Error: Using the sample standard deviations and sizes of each group, we estimate the standard error, which tells us how much we’d expect the means to vary just by chance.
Compute the t-statistic: The t-statistic measures how many standard errors the observed difference is from zero (our null hypothesis value, assuming no difference).
The formula for the t-statistic is:
\[ t = \frac{(\bar{x}_B - \bar{x}_A) - 0}{SE} \]
where:
- \(\bar{x}_A\) and \(\bar{x}_B\) are the sample means for Groups A and B, respectively. The 0 in the numerator represents the null hypothesis value (i.e., no group difference).
- \(SE\) is the pooled standard error of the difference, calculated from the sample standard deviations and sample sizes of the groups:
\[ SE = \sqrt{s_p^2 \left( \frac{1}{n_A} + \frac{1}{n_B} \right)} \]
- \(s_p^2\) is the pooled variance, computed as:
\[ s_p^2 = \frac{(n_A - 1)s_A^2 + (n_B - 1)s_B^2}{n_A + n_B - 2} \]
Here, \(s_A\) and \(s_B\) are the sample standard deviations for Groups A and B, and \(n_A\) and \(n_B\) are the sample sizes for each group.
Press Run Code on the code chunk below to compute the test.
Notice the similarity between the t-statistic that we created using the permutations and the t-statistic in the t_test output (labeled statistic). Also, notice the similarity between the p-value that we created using the permutations and the p-value in the t_test output (labeled p_value).
Tip
Here’s a breakdown of the code for the t_test() function in this context:
wtp_final ~ group: This formula indicates that we are testing the difference in the mean values of willingness to pay between the groups defined by group.var.equal = TRUE: This specifies that the variances of the two groups are assumed to be equal. If set to FALSE, the function would perform Welch’s t-test, which does not assume equal variances.order = c("B", "A"): This specifies the order in which the groups are subtracted. In this case, the mean of group A is subtracted from the mean of group B.alternative = "two-sided": This specifies that the test is two-sided, meaning we are testing if there’s a significant difference in means, regardless of the direction (either group A is greater than group B or vice versa).
Step 9: Test the hypothesis with a simple linear regression
We can equivalently specify the two sample t-test as a simple linear regression. Here, we regress willingness to pay on the dummy coded indicator designed to compare Group B to Group A.
Notice that the independent sample t-test and the simple linear regression produce IDENTICAL results for the difference in willingness to pay between the two groups. An independent samples t-test and a simple linear regression in which the outcome is regressed on a grouping variable are equivalent models — you obtain the same result. In the regression output, the intercept gives the estimated mean willingness to pay for Group A, and the coefficient for groupB represents the difference in means (Group B − Group A).
Wrap-up
Congratulations — you’ve now walked through a complete null hypothesis significance test using permutations, and you’ve seen how it aligns with traditional parametric methods. In this activity, you:
Explored and visualized the observed group means with 95% confidence intervals to see how participants’ willingness to pay varied by visualization type.
Built a null distribution by shuffling labels 1,000 times, creating “permutation intervals” that show what mean differences look like purely by chance under the null hypothesis.
Quantified extremeness by calculating the proportion of permuted differences at least as large as the observed difference — your empirical p-value.
Standardized the test statistic (difference ÷ null SD) to see how many “standard errors” away from zero your result lies.
Verified your findings with a parametric independent samples t-test and an equivalent linear regression, confirming that all approaches yield the same conclusion when assumptions hold.
Key takeaways
Permutation tests make minimal assumptions: they simply ask “what would random chance produce?”
Parametric tests (t-tests, regression) rely on normality and equal‐variance assumptions but are often faster and more familiar.
When both methods agree, you can be confident in your inference; when they diverge, it’s a signal to examine your data and assumptions more closely.
Next steps
Try different comparisons. Repeat the analysis for other pairs of visualization types (e.g., CI vs. CI_rescaled) and compare effect sizes.
Vary the number of permutations. See how the stability of your p-value and null‐distribution estimates changes with fewer (e.g., 500) or more (e.g., 2,000) replicates.
Explore one‐sided tests. If you have a directional hypothesis (e.g., HOPS will increase willingness to pay), adapt your permutation counting accordingly.
By contrasting observed‐data uncertainty (confidence intervals) with null‐model variability (permutation intervals), you’ve gained a deeper intuition for how p-values and other core statistics arise — and, crucially, you’ve de-mystified some of the most confusing concepts in statistics (like p-values) by actually seeing and calculating them via simulation. You now have a flexible, assumption-lean tool in your toolkit to assess group differences — and a clear understanding of how it connects to the familiar t-test and regression frameworks. Happy analyzing!